Hugging Face 是一家在自然语言处理(NLP)和人工智能领域极具影响力的公司,同时它也是一个广受欢迎的开源社区平台。
Hugging Face 由 Clément Delangue、Julien Chaumond 和 Thomas Wolf 于 2016 年创立。最初,它以开发聊天机器人应用程序起步,随后逐渐将重心转移到构建一个专注于自然语言处理的开源平台,旨在降低人工智能技术的使用门槛,让更多人能够参与到相关研究和开发中来。
- 简介:这是 Hugging Face 最具代表性的开源库,基于 Python 和 PyTorch、TensorFlow 等深度学习框架构建。它提供了大量预训练的 Transformer 模型,如 BERT、GPT - 2、RoBERTa 等。
- 作用:这些预训练模型可以用于各种自然语言处理任务,如文本分类、情感分析、命名实体识别、机器翻译等。开发者可以通过简单的代码调用这些模型,快速搭建和训练自己的 NLP 应用,大大节省了研发时间和成本。
- 简介:该库是一个用于自然语言处理任务的数据集集合,包含了众多公开的数据集,如 GLUE、SQuAD、WikiText 等。
- 作用:提供了统一的接口来加载、处理和缓存这些数据集,方便开发者在不同的数据集上进行模型训练和评估。同时,它还支持数据的版本管理和分布式加载,提高了数据处理的效率。
- 简介:这是一个快速且功能强大的分词工具库,支持多种分词算法,如 Byte Pair Encoding(BPE)、WordPiece 等。
- 作用:能够高效地将文本转换为模型可以处理的输入格式,即分词后的词元序列。它的性能优越,在处理大规模数据时具有明显的速度优势。
- 简介:是一个集中存储和分享预训练模型的平台,用户可以在上面找到各种领域和任务的预训练模型。
- 作用:不仅提供了模型的下载和使用接口,还允许用户上传自己训练好的模型,促进了模型的共享和交流。此外,每个模型都有详细的文档和示例代码,方便用户快速上手。
- 社区贡献:Hugging Face 拥有一个活跃的开源社区,全球的研究人员、开发者和爱好者都可以在社区中分享代码、讨论技术问题、贡献模型和数据集。这种开放的社区氛围加速了自然语言处理技术的发展和创新。
- 行业合作:与众多科技公司、研究机构建立了合作关系,共同推动人工智能技术的应用和发展。例如,与谷歌、微软等公司在模型研发和推广方面开展合作。
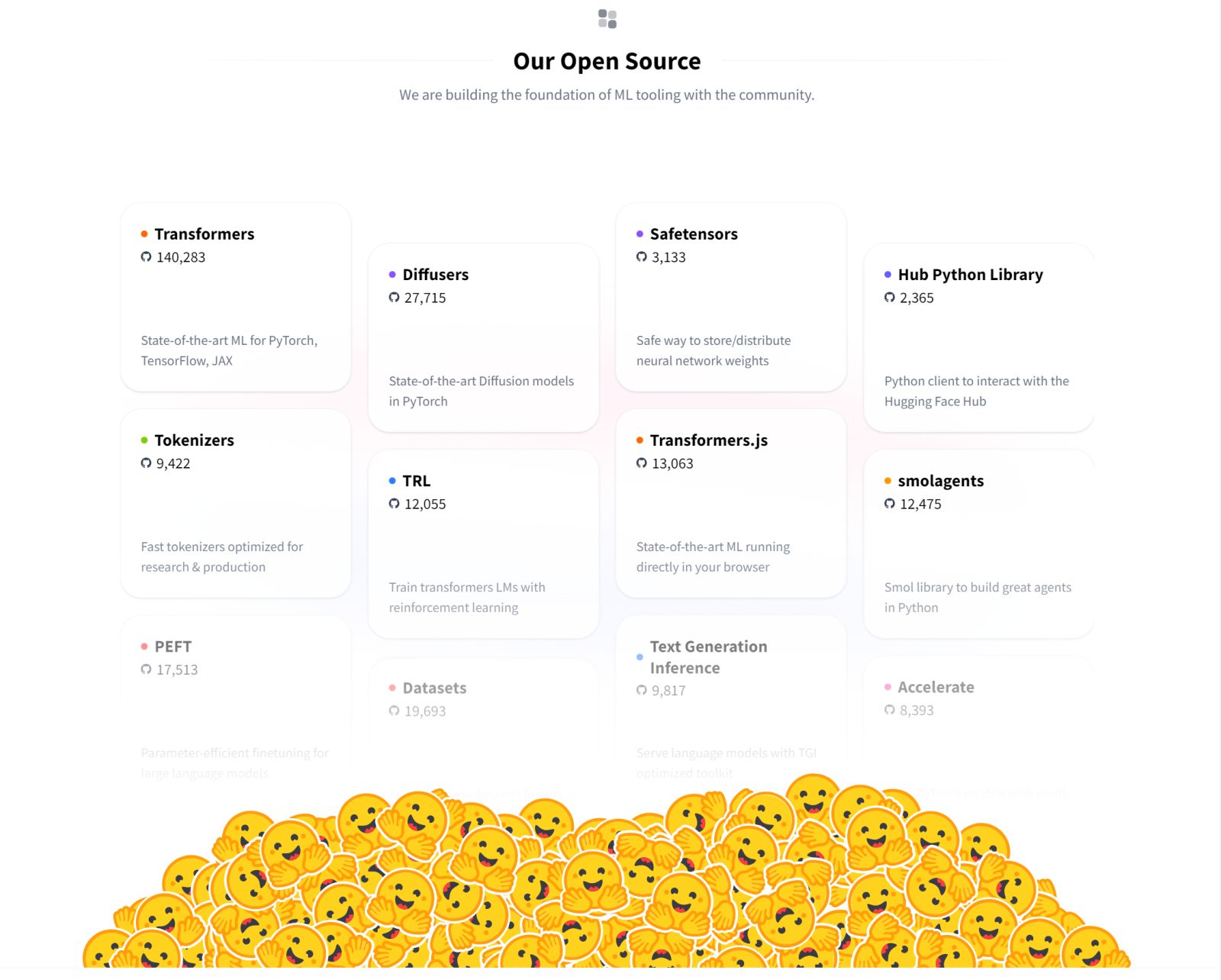
- 科研领域:为研究人员提供了丰富的工具和资源,加速了自然语言处理领域的研究进展。研究人员可以利用预训练模型进行实验和验证新的算法和理论。
- 工业应用:广泛应用于智能客服、机器翻译、信息检索、文本生成等领域。企业可以借助 Hugging Face 的平台和工具,快速开发和部署自己的 NLP 应用,提升业务效率和用户体验。